Author: Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
Date: October 11, 2018 (Last revised: May 24, 2019)
Link: https://arxiv.org/abs/1810.04805
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Introduction
BERT (Bidirectional Encoder Representations from Transformers) represents a paradigm shift in natural language processing. Introduced by researchers at Google AI Language, BERT is a revolutionary language representation model that fundamentally changed how we approach NLP tasks through deep bidirectional pre-training.
The Pre-BERT Landscape
Before BERT, language representation models primarily used unidirectional approaches:
- Left-to-right models: Process text sequentially from beginning to end
- Shallow bidirectionality: Concatenate left-to-right and right-to-left representations
- Task-specific architectures: Required substantial modifications for different NLP tasks
These approaches had significant limitations in capturing full contextual information.
BERT's Revolutionary Approach
Bidirectional Pre-training
BERT's key innovation is pre-training deep bidirectional representations by jointly conditioning on both left and right context in all layers. Unlike previous models, BERT can "see" the entire sentence at once, understanding context from both directions simultaneously.
Traditional (left-to-right): The [cat] → sat → on → the → mat
Traditional (right-to-left): mat ← the ← on ← sat ← The [cat]
BERT (bidirectional): The ← [cat] → sat
↑
(sees full context)
Two-Stage Framework
BERT operates in two stages:
- Pre-training: Train on unlabeled data over different pre-training tasks
- Fine-tuning: Initialize with pre-trained parameters and fine-tune on downstream tasks
Pre-training Tasks
BERT uses two unsupervised tasks for pre-training:
1. Masked Language Model (MLM)
The MLM task randomly masks 15% of tokens and trains the model to predict them:
def create_masked_lm_predictions(tokens, masked_lm_prob=0.15):
"""
Create masked language model predictions
Args:
tokens: Input token sequence
masked_lm_prob: Probability of masking each token
Returns:
Masked tokens and labels
"""
masked_tokens = tokens.copy()
labels = []
for i, token in enumerate(tokens):
# Mask with probability
if random.random() < masked_lm_prob:
prob = random.random()
if prob < 0.8:
# 80% of time: replace with [MASK]
masked_tokens[i] = '[MASK]'
elif prob < 0.9:
# 10% of time: replace with random token
masked_tokens[i] = random.choice(vocab)
# 10% of time: keep original
labels.append(token)
else:
labels.append(None)
return masked_tokens, labels
Example:
Original: "The quick brown fox jumps over the lazy dog"
Masked: "The [MASK] brown fox [MASK] over the lazy dog"
Predict: "quick" and "jumps"
2. Next Sentence Prediction (NSP)
The NSP task trains BERT to understand relationships between sentences:
def create_nsp_training_data(document):
"""
Create next sentence prediction training pairs
Args:
document: Document containing multiple sentences
Returns:
Sentence pairs with labels (IsNext or NotNext)
"""
training_pairs = []
sentences = split_into_sentences(document)
for i in range(len(sentences) - 1):
sentence_a = sentences[i]
# 50% of time: actual next sentence (positive example)
if random.random() < 0.5:
sentence_b = sentences[i + 1]
label = 'IsNext'
# 50% of time: random sentence (negative example)
else:
sentence_b = random.choice(sentences)
label = 'NotNext'
training_pairs.append((sentence_a, sentence_b, label))
return training_pairs
BERT Architecture
Model Configurations
BERT comes in two main sizes:
BERT_BASE:
- Layers (L): 12
- Hidden size (H): 768
- Attention heads (A): 12
- Total parameters: 110M
BERT_LARGE:
- Layers (L): 24
- Hidden size (H): 1024
- Attention heads (A): 16
- Total parameters: 340M
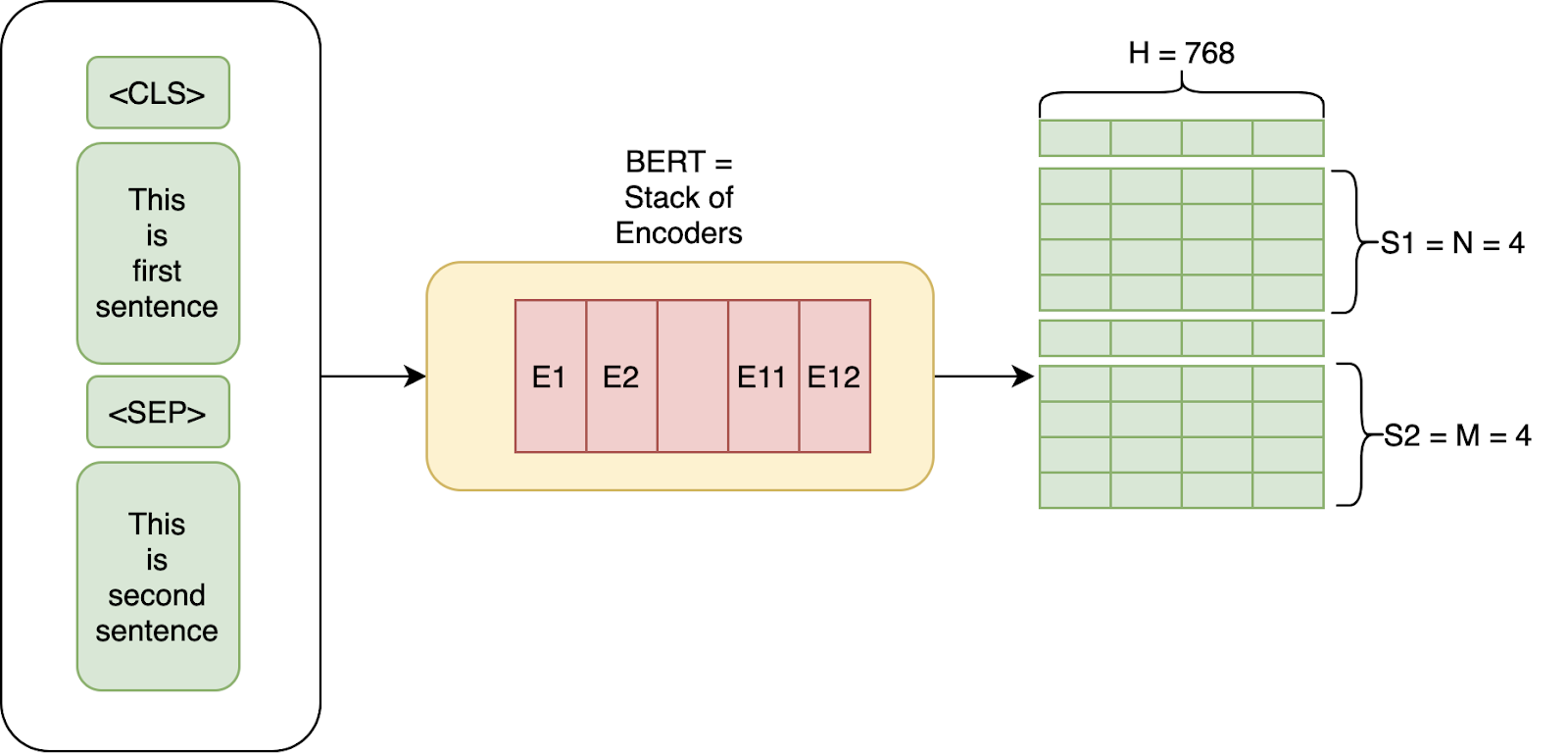
Input Representation
BERT's input combines three types of embeddings:
class BERTEmbedding:
def __init__(self, vocab_size, hidden_size, max_position, type_vocab_size):
# Token embeddings: vocabulary
self.token_embedding = nn.Embedding(vocab_size, hidden_size)
# Positional embeddings: position in sequence
self.position_embedding = nn.Embedding(max_position, hidden_size)
# Segment embeddings: distinguish sentence A from sentence B
self.segment_embedding = nn.Embedding(type_vocab_size, hidden_size)
self.layer_norm = nn.LayerNorm(hidden_size)
def forward(self, token_ids, segment_ids, position_ids):
# Sum all embeddings
token_embed = self.token_embedding(token_ids)
position_embed = self.position_embedding(position_ids)
segment_embed = self.segment_embedding(segment_ids)
embeddings = token_embed + position_embed + segment_embed
embeddings = self.layer_norm(embeddings)
return embeddings
Special Tokens
BERT uses special tokens for different purposes:
- [CLS]: Classification token (first token of every sequence)
- [SEP]: Separator token (separates sentences)
- [MASK]: Mask token (for MLM task)
- [PAD]: Padding token
Fine-tuning for Downstream Tasks
One of BERT's most powerful features is its simplicity in fine-tuning:
Single Sentence Classification
class BERTClassifier(nn.Module):
def __init__(self, bert_model, num_classes):
super().__init__()
self.bert = bert_model
self.classifier = nn.Linear(bert_model.config.hidden_size, num_classes)
def forward(self, input_ids, attention_mask, token_type_ids):
# Get BERT output
outputs = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids
)
# Use [CLS] token representation for classification
pooled_output = outputs.pooler_output
# Classification layer
logits = self.classifier(pooled_output)
return logits
Question Answering
class BERTForQuestionAnswering(nn.Module):
def __init__(self, bert_model):
super().__init__()
self.bert = bert_model
self.qa_outputs = nn.Linear(bert_model.config.hidden_size, 2)
def forward(self, input_ids, attention_mask):
# Get BERT sequence output
outputs = self.bert(
input_ids=input_ids,
attention_mask=attention_mask
)
sequence_output = outputs.last_hidden_state
# Predict start and end positions
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = logits.split(1, dim=-1)
return start_logits.squeeze(-1), end_logits.squeeze(-1)
Benchmark Results
BERT achieved state-of-the-art results across multiple NLP benchmarks:
GLUE Benchmark
The General Language Understanding Evaluation (GLUE) benchmark:
- BERT_BASE: 78.5% average score
- BERT_LARGE: 80.5% average score
- Improvement: 7.7 percentage points absolute improvement
SQuAD (Question Answering)
Stanford Question Answering Dataset results:
SQuAD v1.1:
- Test F1: 93.2
- Improvement: 1.5 points absolute
SQuAD v2.0:
- Test F1: 83.1
- Improvement: 5.1 points absolute
MultiNLI (Natural Language Inference)
- Accuracy: 86.7%
- Improvement: 4.6% absolute
Named Entity Recognition (NER)
On CoNLL-2003 NER:
- F1 Score: 92.8
- New state-of-the-art
Technical Innovations
Bidirectional Context
The bidirectional nature allows BERT to understand nuanced meanings:
Example: "The bank of the river"
- Left context: "The bank" → could be financial institution
- Right context: "of the river" → clarifies it's a riverbank
- BERT sees both: correctly identifies riverbank context
Transfer Learning Excellence
BERT's pre-trained representations transfer exceptionally well:
# Pre-trained on general text
bert_base = load_pretrained_bert()
# Fine-tune for specific task with minimal data
task_model = BERTClassifier(bert_base, num_classes=3)
train(task_model, task_data, epochs=3) # Often just 2-4 epochs!
WordPiece Tokenization
BERT uses WordPiece tokenization to handle rare words:
Input: "unbelievable"
Tokens: ["un", "##believe", "##able"]
This enables BERT to handle out-of-vocabulary words effectively.
Impact on NLP
BERT's impact on the field has been transformative:
1. Pre-training Paradigm
Established pre-training + fine-tuning as the standard approach for NLP:
General Pre-training → Task-Specific Fine-tuning
(Large unlabeled data) → (Small labeled data)
2. Democratization of NLP
Made state-of-the-art NLP accessible:
- Download pre-trained BERT
- Fine-tune on your task
- Achieve excellent results
3. Research Catalyst
Inspired numerous variants and improvements:
- RoBERTa: Robustly Optimized BERT
- ALBERT: A Lite BERT
- DistilBERT: Distilled version
- ELECTRA: More efficient pre-training
- SpanBERT: Span-based pre-training
4. Multilingual Models
BERT demonstrated effective multilingual learning:
- Multilingual BERT supports 104 languages
- Shows cross-lingual transfer capabilities
Practical Applications
BERT has been deployed in numerous real-world applications:
Search Engines
Google integrated BERT into Search:
- Better understanding of search queries
- Improved contextual relevance
- Handling of conversational queries
Chatbots and Virtual Assistants
Enhanced understanding of:
- User intent
- Contextual conversation flow
- Nuanced language patterns
Content Recommendation
Improved content matching based on:
- Semantic similarity
- Contextual relevance
- User intent understanding
Best Practices for Using BERT
1. Choose the Right Model Size
# For resource-constrained environments
model = BertModel.from_pretrained('bert-base-uncased')
# For maximum performance
model = BertModel.from_pretrained('bert-large-uncased')
# For specific domains
model = BertModel.from_pretrained('bert-base-cased')
2. Proper Fine-tuning
# Learning rate scheduling
optimizer = AdamW(model.parameters(), lr=2e-5)
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=num_warmup_steps,
num_training_steps=num_training_steps
)
# Gradient clipping
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
# Few epochs (usually 2-4)
for epoch in range(3):
train_epoch(model, train_dataloader, optimizer, scheduler)
3. Task-Specific Adaptations
Different tasks require different approaches:
- Classification: Use [CLS] token
- Token classification: Use all token representations
- Question answering: Predict span start and end
- Sentence pairs: Use [SEP] to separate
Limitations and Considerations
While revolutionary, BERT has limitations:
1. Computational Requirements
- Large memory footprint
- Slow inference for real-time applications
- Requires significant GPU resources
2. Maximum Sequence Length
- Limited to 512 tokens
- Long documents require truncation or splitting
3. Domain Adaptation
- General pre-training may not capture domain-specific language
- May require domain-specific pre-training
Conclusion
BERT represents a watershed moment in natural language processing. By introducing deep bidirectional pre-training, it demonstrated that:
- Bidirectional context is crucial for language understanding
- Pre-training + fine-tuning is a powerful paradigm
- Transfer learning works exceptionally well for NLP
- Simplicity in design can lead to remarkable results
The impact of BERT extends far beyond its impressive benchmark results. It democratized state-of-the-art NLP, inspired countless research directions, and fundamentally changed how we approach language understanding tasks.
BERT's legacy continues through its many successors and variants, and its core principles remain foundational to modern NLP. Whether you're building a chatbot, improving search, or developing language understanding systems, BERT's innovations provide the foundation for success.
Citation:
@article{devlin2018bert,
title={BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding},
author={Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1810.04805},
year={2018}
}